 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Capture is Not the Target Domain: Scaling Synthetic Data for Learning Motion Representations
Feb 11, 2026Synthetic data offers a compelling path to scalable pretraining when real-world data is scarce, but models pretrained on synthetic data often fail to transfer reliably to deployment settings. We study this problem in full-body human motion, where large-scale data collection is infeasible but essential for wearable-based Human Activity Recognition (HAR), and where synthetic motion can be generated from motion-capture-derived representations. We pretrain motion time-series models using such synthetic data and evaluate their transfer across diverse downstream HAR tasks. Our results show that synthetic pretraining improves generalisation when mixed with real data or scaled sufficiently. We also demonstrate that large-scale motion-capture pretraining yields only marginal gains due to domain mismatch with wearable signals, clarifying key sim-to-real challenges and the limits and opportunities of synthetic motion data for transferable HAR representations.
ActiNet: Activity intensity classification of wrist-worn accelerometers using self-supervised deep learning
Oct 02, 2025



The use of reliable and accurate human activity recognition (HAR) models on passively collected wrist-accelerometer data is essential in large-scale epidemiological studies that investigate the association between physical activity and health outcomes. While the use of self-supervised learning has generated considerable excitement in improving HAR, it remains unknown the extent to which these models, coupled with hidden Markov models (HMMs), would make a tangible improvement to classification performance, and the effect this may have on the predicted daily activity intensity compositions. Using 151 CAPTURE-24 participants' data, we trained the ActiNet model, a self-supervised, 18-layer, modified ResNet-V2 model, followed by hidden Markov model (HMM) smoothing to classify labels of activity intensity. The performance of this model, evaluated using 5-fold stratified group cross-validation, was then compared to a baseline random forest (RF) + HMM, established in existing literature. Differences in performance and classification outputs were compared with different subgroups of age and sex within the Capture-24 population. The ActiNet model was able to distinguish labels of activity intensity with a mean macro F1 score of 0.82, and mean Cohen's kappa score of 0.86. This exceeded the performance of the RF + HMM, trained and validated on the same dataset, with mean scores of 0.77 and 0.81, respectively. These findings were consistent across subgroups of age and sex. These findings encourage the use of ActiNet for the extraction of activity intensity labels from wrist-accelerometer data in future epidemiological studies.
Reducing Annotation Burden in Physical Activity Research Using Vision-Language Models
May 06, 2025Introduction: Data from wearable devices collected in free-living settings, and labelled with physical activity behaviours compatible with health research, are essential for both validating existing wearable-based measurement approaches and developing novel machine learning approaches. One common way of obtaining these labels relies on laborious annotation of sequences of images captured by cameras worn by participants through the course of a day. Methods: We compare the performance of three vision language models and two discriminative models on two free-living validation studies with 161 and 111 participants, collected in Oxfordshire, United Kingdom and Sichuan, China, respectively, using the Autographer (OMG Life, defunct) wearable camera. Results: We found that the best open-source vision-language model (VLM) and fine-tuned discriminative model (DM) achieved comparable performance when predicting sedentary behaviour from single images on unseen participants in the Oxfordshire study; median F1-scores: VLM = 0.89 (0.84, 0.92), DM = 0.91 (0.86, 0.95). Performance declined for light (VLM = 0.60 (0.56,0.67), DM = 0.70 (0.63, 0.79)), and moderate-to-vigorous intensity physical activity (VLM = 0.66 (0.53, 0.85); DM = 0.72 (0.58, 0.84)). When applied to the external Sichuan study, performance fell across all intensity categories, with median Cohen's kappa-scores falling from 0.54 (0.49, 0.64) to 0.26 (0.15, 0.37) for the VLM, and from 0.67 (0.60, 0.74) to 0.19 (0.10, 0.30) for the DM. Conclusion: Freely available computer vision models could help annotate sedentary behaviour, typically the most prevalent activity of daily living, from wearable camera images within similar populations to seen data, reducing the annotation burden.
Self-supervised Learning for Human Activity Recognition Using 700,000 Person-days of Wearable Data
Jun 06, 2022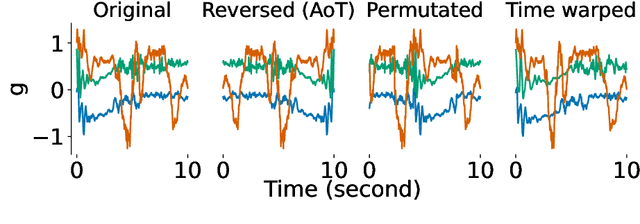
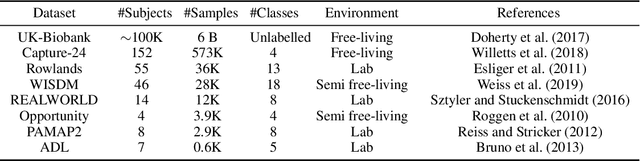
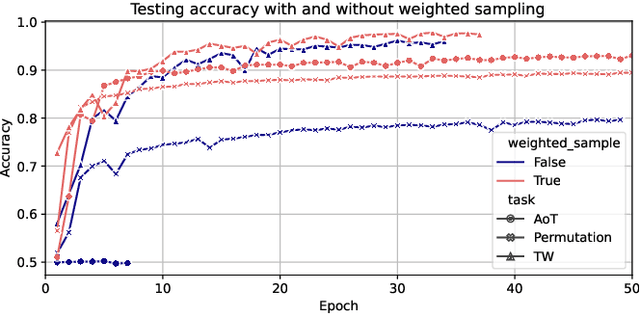
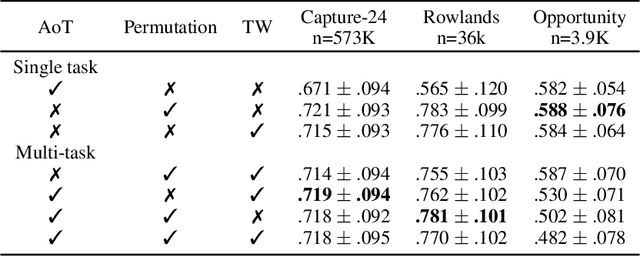
Advances in deep learning for human activity recognition have been relatively limited due to the lack of large labelled datasets. In this study, we leverage self-supervised learning techniques on the UK-Biobank activity tracker dataset--the largest of its kind to date--containing more than 700,000 person-days of unlabelled wearable sensor data. Our resulting activity recognition model consistently outperformed strong baselines across seven benchmark datasets, with an F1 relative improvement of 2.5%-100% (median 18.4%), the largest improvements occurring in the smaller datasets. In contrast to previous studies, our results generalise across external datasets, devices, and environments. Our open-source model will help researchers and developers to build customisable and generalisable activity classifiers with high performance.
Semi-unsupervised Learning of Human Activity using Deep Generative Models
Oct 29, 2018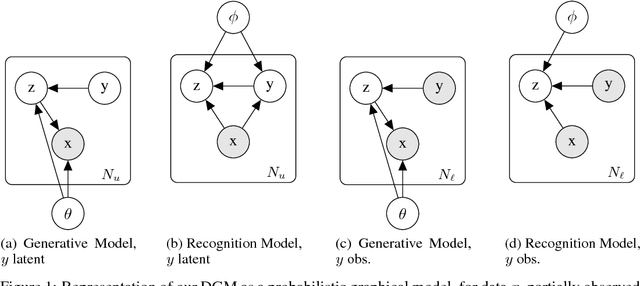
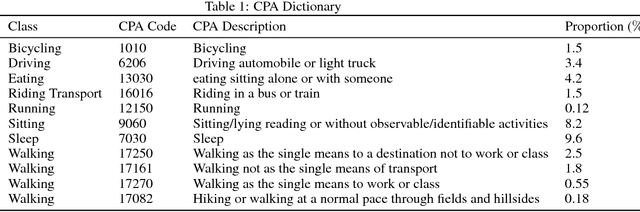
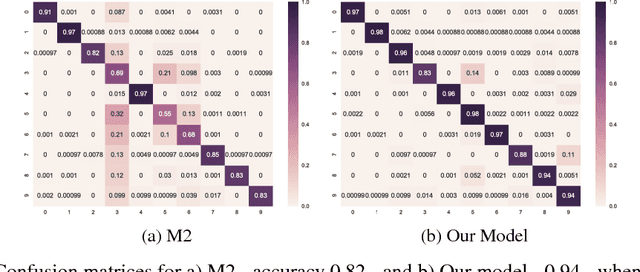
Here we demonstrate a new deep generative model for classification. We introduce `semi-unsupervised learning', a problem regime related to transfer learning and zero/few shot learning where, in the training data, some classes are sparsely labelled and others entirely unlabelled. Models able to learn from training data of this type are potentially of great use, as many medical datasets are `semi-unsupervised'. Our model demonstrates superior semi-unsupervised classification performance on MNIST to model M2 from Kingma and Welling (2014). We apply the model to human accelerometer data, performing activity classification and structure discovery on windows of time series data.